Fleet Configuration Management
Table of Contents
This post explains the challenge of fleet configuration management, the role of an automated fleet configuration management system, and describes key considerations for building such a system. This post is also publised to the Microsoft ISE Developer Blog. Recently, my team at Microsoft completed a customer engagement that involved managing edge deployments onto factory floors across geographical locations. This system needed to support existing workloads migrated from Azure IoT Hub, new workloads for processing IoT data feeds, and machine learning workloads for performing inference to ship intelligence to the edge. During this engagement, we built a system to handle this complexity using Kalypso to orchestrate GitOps deployments across a fleet of arc-enabled Kubernetes clusters hosting Azure IoT Operations to support cloud connectivity and IoT device telemetry. This post explains the challenge of fleet configuration management, the role of an automated fleet configuration management system, and describes key considerations for building such a system. An automated fleet configuration management system is essential in a scenario where many workloads or applications need to be deployed and managed across a fleet of hosting platforms. This can be the case for cloud hosted platforms serving separate purposes, or edge hosted platforms where workloads need to be distributed across separate locations. There are a few options for implementing a fleet configuration management system. The one that works best for a given scenario will depend on details such as the hosting platforms that they support, licensing, and operational requirements. All of these options require managing a single separate Kubernetes cluster to run the automation work of the system. Before getting into the details, lets first define terms as they appear in this post. Generally, a fleet is composed of many hosting platforms, and there are many workloads that are deployed, each with a unique set of configuration. The specific details will depend on what the hosting platform and workloads are, but for this post, we will use Kubernetes clusters as the fleet, Helm charts as workloads, and rendered Kubernetes objects (manifests) as configuration. We will also assume that the workloads are deployed using GitOps principles, where the configuration is stored in a Git repository and monitored by GitOps agents (e.g. Flux) running on clusters in the fleet. Fleet configuration management solves a problem that only becomes apparent when managing many workloads across many clusters. This next series of diagrams outlines the problem as the number of clusters and workloads scales up from a single workload and cluster, to many workloads across many clusters. The simplest scenario starts with one workload being deployed into one cluster. The workload’s Kubernetes manifests are committed into a GitHub repository that is monitored by the Flux GitOps agent. When a change is made to the workload’s Kubernetes manifests, that change is detected and applied automatically in the cluster. For the workload to be deployed to a fleet of Kubernetes clusters, each cluster just needs to host its own Flux agent that is configured to watch the same set of Kubernetes manifests for the workload. When a change is made to the workload’s Kubernetes manifests, that change is detected and applied by each Flux agent independently. This enables one instance of the workload to be deployed into each cluster in the fleet. However, it is usually the case that each instance of this workload needs to be configured differently. This is because clusters in a fleet will often serve different purposes, and configuration must be applied to reflect that. For example, different hostnames, workload scaling behaviors, or feature flags might need to be controlled separately for different clusters in the fleet. This can be made possible by providing multiple configurations as part of the workload’s Kubernetes manifests and modifying the Flux agents to watch their own dedicated configurations. This enables independent configuration for each instance of the workload at the cost of additional complexity for managing configuration manifests and Flux agents. To support additional workloads, the same setup needs to be replicated. Each workload will have its own set of Kubernetes manifests that each contains configuration for each cluster in the fleet and each flux agent needs to know what configurations to watch. While this works and can be manageable for a small number of workloads and clusters, the complexity of manually creating workload configurations does not scale well as the number of workloads and clusters increases. Each workload must provide a unique set of configurations for each cluster in the fleet, and each cluster must be configured to watch the appropriate manifests. A fleet configuration management system is an automated system that aims to simplify the complexities of manually managing workload configurations for the fleet. These systems serve 3 purposes: Configuration management systems provide automation to reduce the amount of manual configuration from multiplicative scaling to additive scaling by the number of workloads and clusters in the fleet. This allows engineering and operations teams to easily scale the number of workloads and clusters. When a new workload or cluster is added, it only needs to be registered with the fleet configuration management system. The system will then automatically compose and deliver the appropriate configurations to the clusters in the fleet. Registering workloads and clusters with a fleet configuration management system requires managing higher-level deployment abstractions and managing a system that operates on these abstractions to automate configuration delivery. This adds complexity to the system and requires additional operational overhead. It is important to weigh this cost against the cost of manually curating workload configurations in your system. This is an example architecture that generalizes the architecture that we built in our recent customer engagement. For more details on getting started with Kalypso, see its GitHub repositories and the following Microsoft Learn pages: This architecture serves two personas: the Application Engineer and the Platform Engineer. There may be many different Application Engineers, one for each independent workload. The Application Engineer owns and authors workloads that run within the fleet of Kubernetes clusters. Each workload has its own independent software development lifecycle that is defined and practiced by the Application Engineer. The Platform Engineer owns and manages the Kalypso Fleet Configuration Management Cluster. This service facilitates the complexities of generating and distributing the appropriate configuration across the fleet for all workloads. To learn more about how Application Engineers and Platform Engineers use this system, see the Kalypso Runbooks in Kalypso’s documentation. These runbooks provide step-by-step instructions on the common Kalypso use cases and include examples for each scenario. Fleet configuration management is a powerful tool for scaling configuration management for many different workloads across many different hosting platforms. These systems automate the tedious work of managing individual configuration files by using higher level abstractions to compose and deliver configuration to the fleet. Thank you to the rest of the ISE dev crew who helped with the customer engagement that inspired this post Bindu Chinnasamy, John Hauppa, Uffaz Nathaniel, Bryan Leighton, Laura Lund, and Kanishk Tantia. And a special thank you to Eugene Fedorenko for his expertise and guidance on using Kalypso. This post is also publised to the Microsoft ISE Developer Blog.Introduction
What Is Fleet Configuration Management?
Example Fleet Configuration Management Systems
Definitions
What Problem Does Fleet Configuration Management Solve?
One Workload, One Cluster
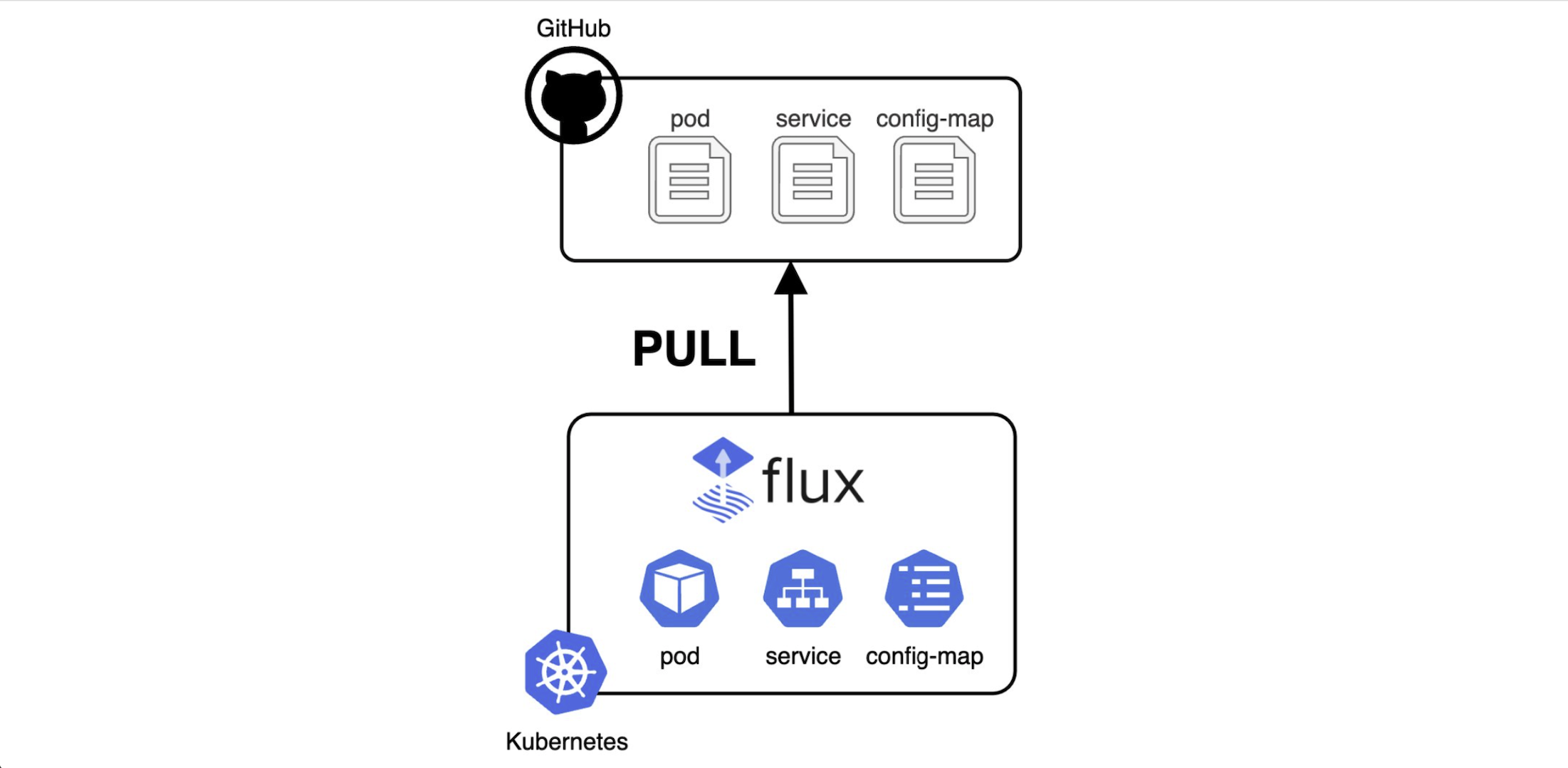
One Workload, Many Clusters
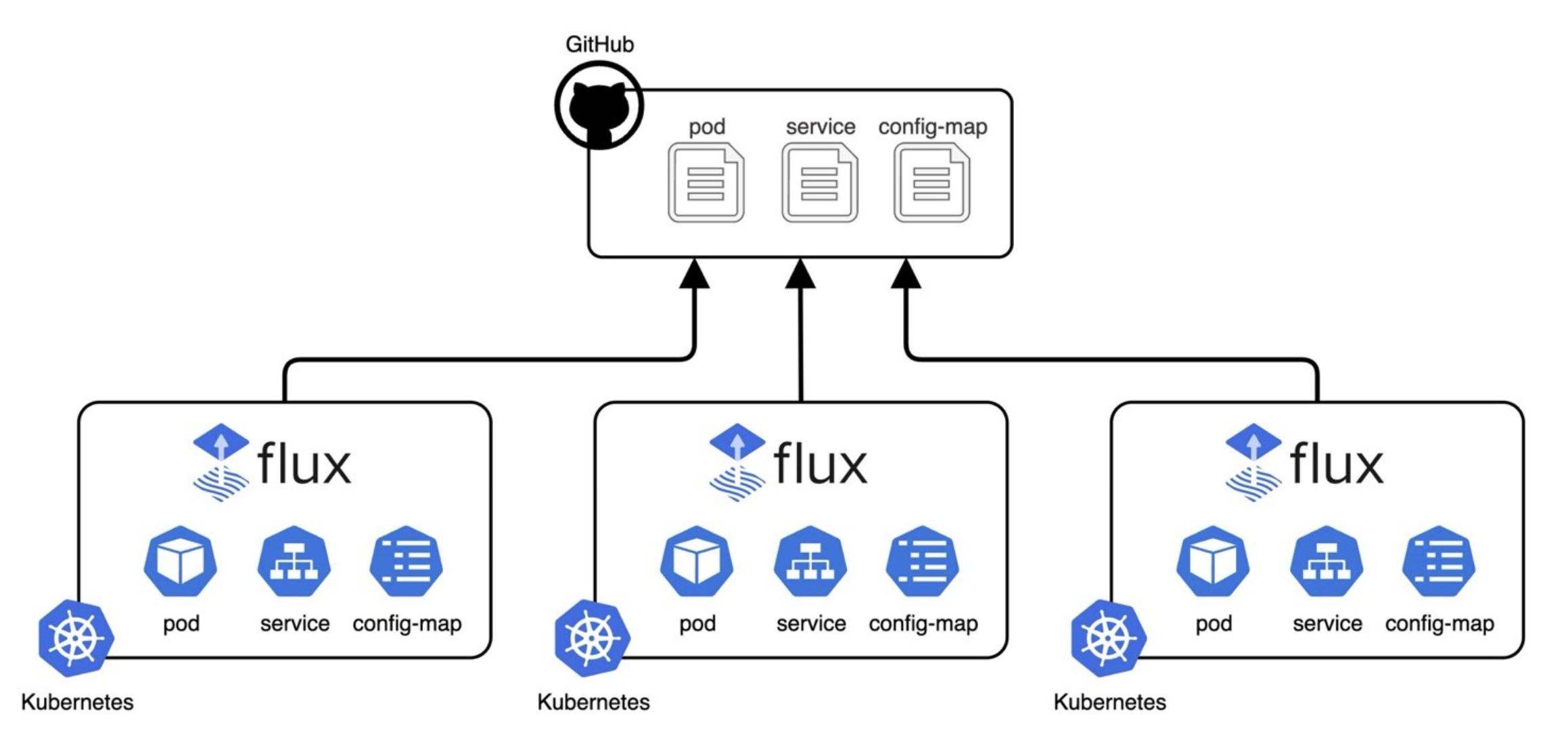
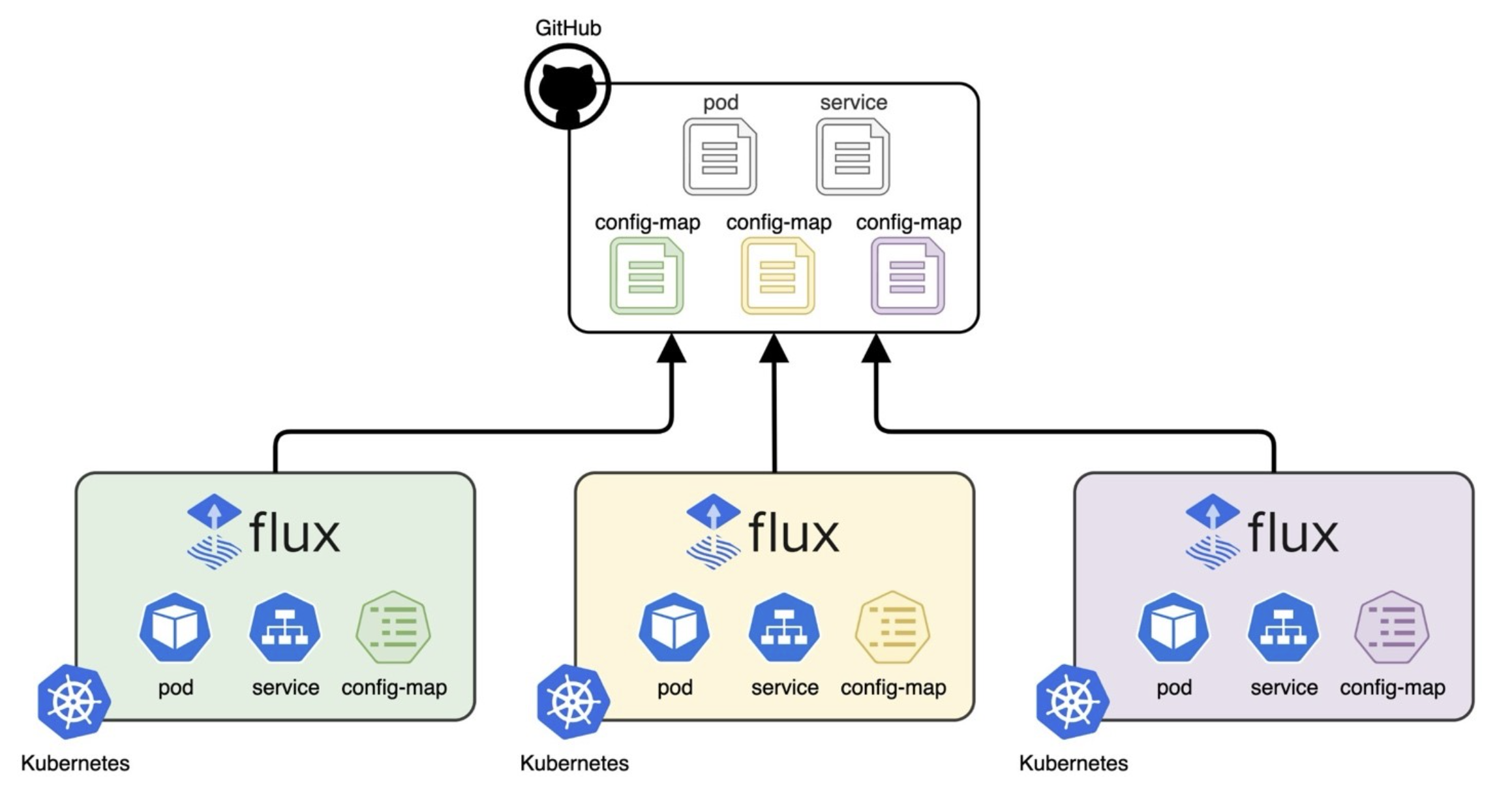
Many Workloads, Many Clusters
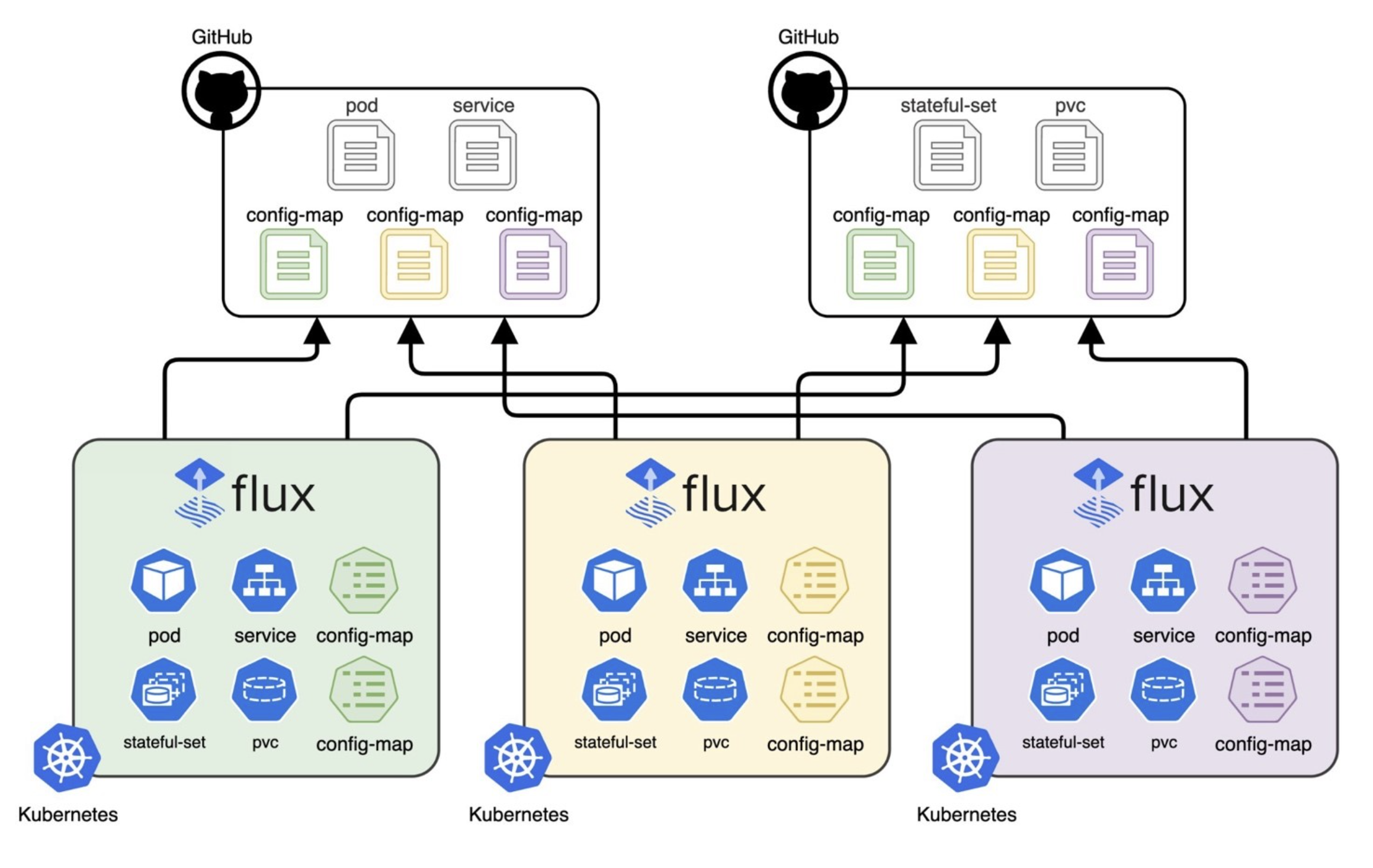
The Role of a Configuration Management System
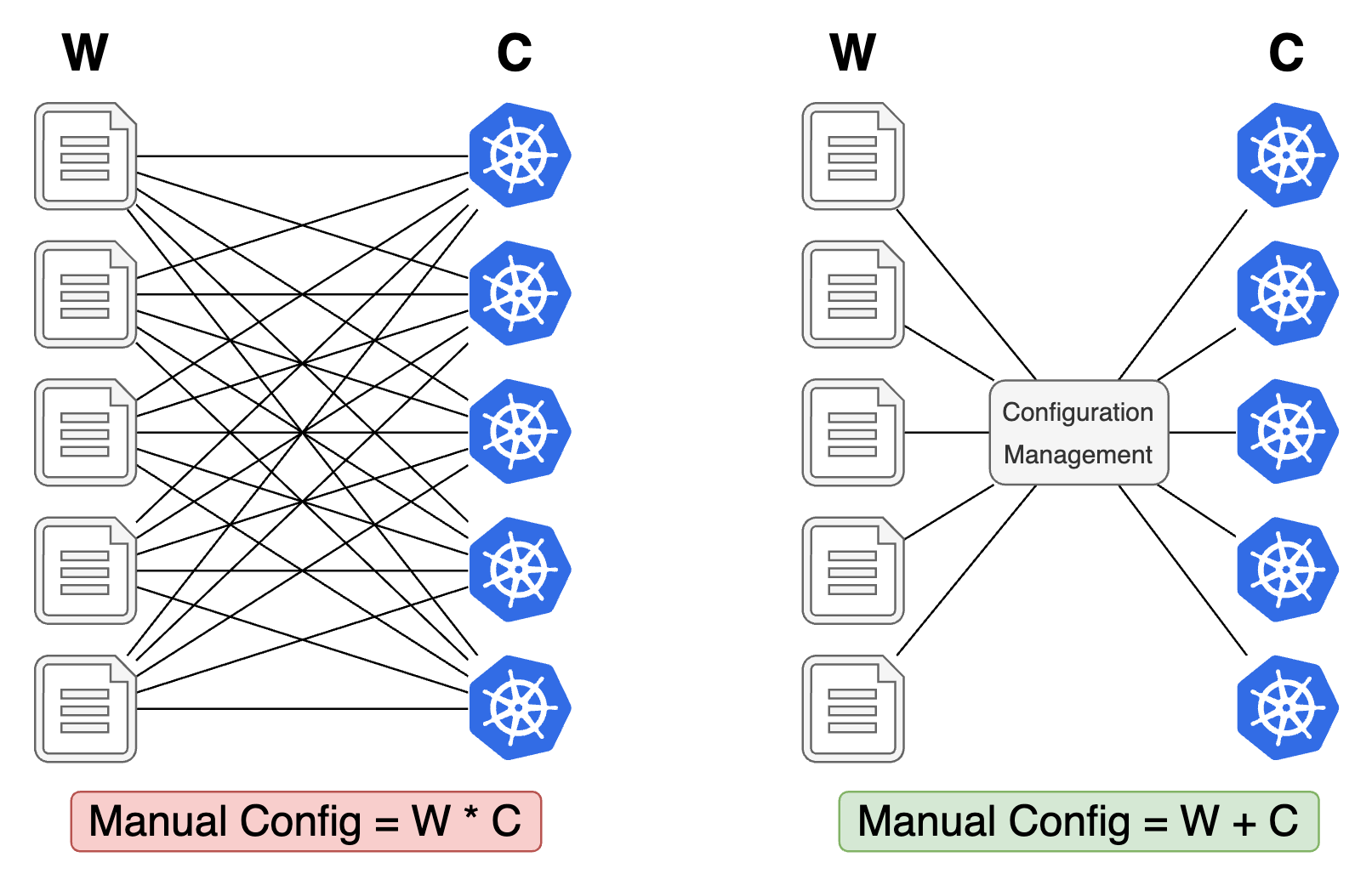
Do I Need A Fleet Configuration Management System?
Example Architecture With Kalypso
Personas
Architecture Diagram
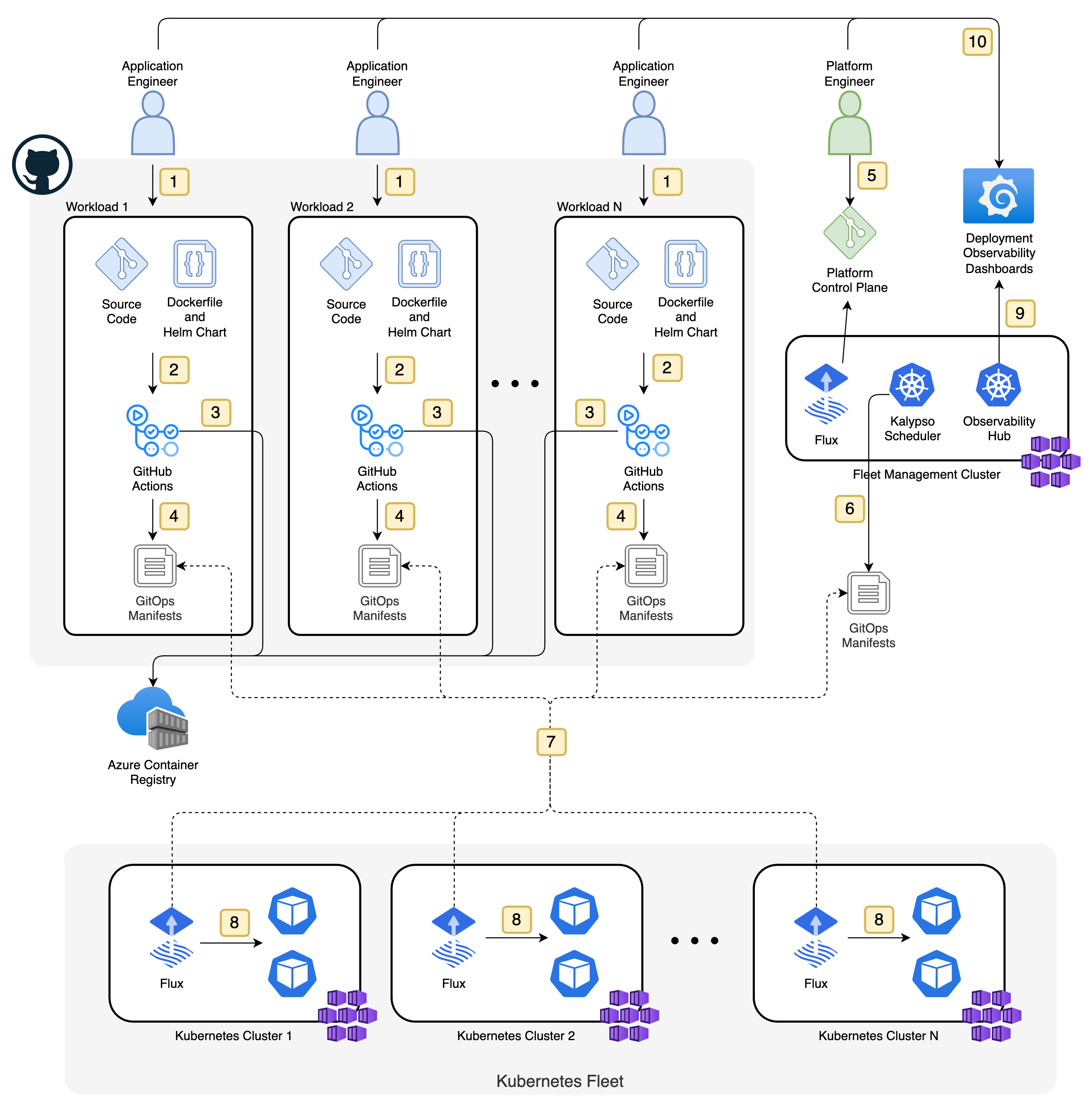
System Workflow
Kalypso Runbooks
Conclusion
Acknowledgements
ISE Developer Blog